SLOVENE PARSER
|
To play around with the parser click on the image on the left or follow link. You can also download the parser. |
WHAT IS A PARSER?
A parser is a computer program for determining automatically the grammatical structure of a sentence. From linguistic point of view automatized syntactic parsing of large quantities of texts enables research of various syntactic phenomena in Slovene as it is used in real texts. Syntactic parsing represents also one of the basic natural language processing procedures which supports more complex language technologies such as machine translation, information extraction, speech technologies, automatic summarization, question-answering etc.
WHICH PARSING METHOD DID WE USE?
The dependency treebank model which was developed in the Linguistic Annotation of Slovene project was also used for syntactic parsing resources and applications in Communication in Slovene project. This model follows basic guidelines of syntactic parsing from the established resources such as Prague Dependeny Treebank, but it is considerably simpler. It reduces the number of possible dependencies to 10 and lays down easier to follow guidelines for manual annotation. To avoid confusion between traditional syntactic categories as they are used in traditional grammars (subject, object, adverbial etc.) and the ones used in automatic parsing different label names were used, as the two systems are not directly translatable. This does not mean they are not comparable – which is also shown in the table below.
|
Groups of labels |
Labels |
Description |
|
First level labels link elements in different types of phrases. |
dol |
Links heads and modifiers in phrases. |
|
del |
Links parts of verbal phrases. | |
|
prir |
Links heads in coordinate structures within clauses. | |
|
vez |
Links words or commas in conjuctive function. | |
|
skup |
Links (function) words in frozen multi-word structures. | |
|
Second level labels link sentence elements. |
ena |
Clause subject. |
|
dve |
Clause object. | |
|
tri |
Adverbial of manner. | |
|
štiri |
Other adverbials. | |
|
Third level label links all other structures. |
modra |
Links to the root, punctuation, syntactically less predictable structures, parentheses etc. |
A more detailed description of lables and their relation to the traditional syntactic categories is available in the manual for training corpus annotators (in Slovene).
HOW CAN I TEST THE PARSER?
You can test the parser on the following web page: http://razčlenjevalnik.slovenščina.eu. This web service is intended for parsing shorter untagged texts which are both tagged and parsed in the process. As the XML-TEI format is intended mainly for computers we also developed an interface which transforms the data into a dependency tree visuals. To parse larger quantities of texts or already tagged texts you can use a downloadable application.
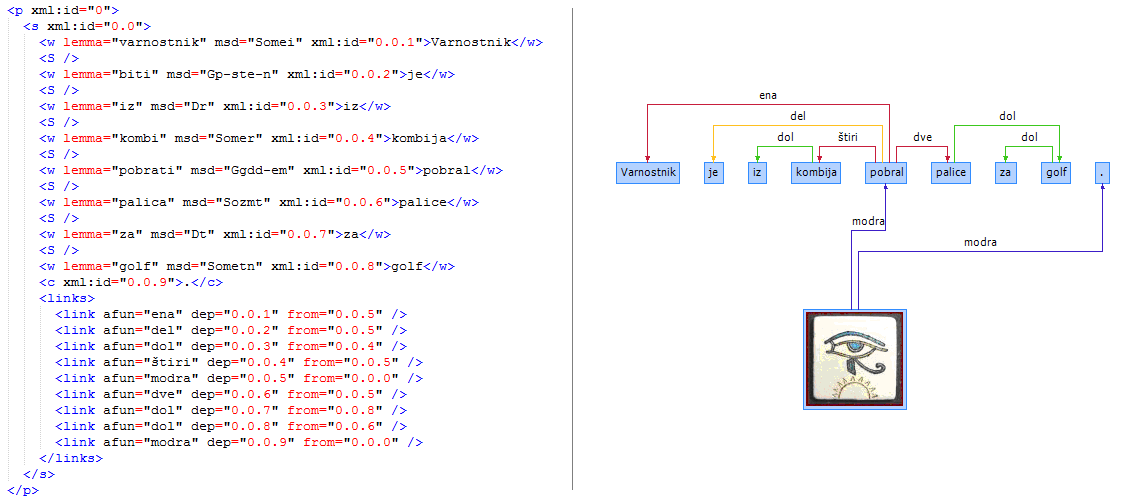
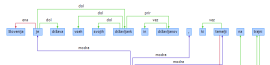
An example of a parsed sentence in the XML-TEI format (left) and its visualization (right).
HOW DOES THE PARSER ACTUALLY WORK?
Our statistical parser is based on the open source MSTParser which uses maximum spanning tree in directed graphs as a method. The manual used by annotators and downloadable application can be found on this web page. Programs in the application were partly developed in Microsoft Visual Studio 2010 and partly in Java. To run the application .NET Framework 4.0 in Java 1.6 environments are needed.
DEPENDENCY TREEBANK VIEWER AND EDITOR
A program for viewing and editing dependency treebanks was developed for visualization and annotation purposes. You can also search treebanks using relatively complex queries. The program is freely available and can be downloaded (see the link below). It was developed for Windows environment – to install it unpack it and run the setup.exe file. To check a sample of the dependency treebank download and open the part of the training corpus with the manually annotated dependency trees.
LICENCE AND DOWNLOAD
The parser is freely available as a web service and as an application which can be downloaded and used for parsing larger quantities of texts. The parser is available on the download web page. It can be used and distributed under Apache License v2.0, and the same licence is used for the treebank viewer program.
Click on the link to download:
1. treebank viewer and editor.
2. syntactically annotated part of the training corpus for viewing and searching in the treebank viewer. The size of the file is 4.3MB.
AUTORS AND COLLABORATORS
Adaptation and upgrade of MSTParser for Slovene: Jan Rupnik
The Obeliks tagger: Miha Grčar, Matjaž Juršič, Jan Rupnik, Simon Krek, Kaja Dobrovoljc
Treebank viewer and editor: Janez Brank
BIBLIOGRAPHY
Kaja Dobrovoljc, Simon Krek, Jan Rupnik (2012): Skladenjski razčlenjevalnik za slovenščino. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan.
Nina Ledinek, Tomaž Erjavec: Odvisnostno površinskoskladenjsko označevanje slovenščine: specifikacije in označeni korpusi. Zbornik Simpozija Obdobja: Infrastruktura slovenščine in slovenistike, Ljubljana, 2009.
R. McDonald, K. Lerman, and F. Pereira (2006): Multilingual Dependency Parsing with a Two-Stage Discriminative Parser. Tenth Conference on Computational Natural Language Learning (CoNLL-X).
