GIGAFIDA – WRITTEN CORPUS

|
To play around with the Gigafida web concordancer click on the image on the left or follow link. |
WHAT IS GIGAFIDA?
Corpora are digital collections of authentic texts collected for a particular purpose according to criteria defined in advance. Usually, corpora are available together with tools for the analysis and exploration of language data. The Gigafida corpus is an extensive collection of Slovene text of various genres, from daily newspapers, magazines, all kinds of books (fiction, non-fiction, textbooks), web pages, transcriptions of parliamentary debates and similar. It contains almost 1.2 billion words, or exactly 1,187,002,502 words.
WHY DID WE BUILD GIGAFIDA?
Gigafida was built for all of us to be able to research modern Slovene on various levels. On one hand, it provides answers to immediate queries via the web concordancer, and more importantly, it provides extensive data about the Slovene language as it has been used in the last – a little more than – twenty years. In this respect, it represents the only relatively reliable source of information for the compliation of dictionaries and grammars of modern Slovene, for various language reference guides about modern Slovene, and for Slovene language technologies.
In a more narrow sense, Gigafida represents the starting point for presentation of modern Slovene in resources and applications developed within the Communication in Slovene project, in the pedagogic grammar portal, ortography guide and Slovene lexical database, both as the source of automatically or manually extracted data and their interpretation, and as the source of concrete examples of language use.
WHO ARE THE USERS OF GIGAFIDA?
Gigafida is intended not only for linguists and language specialists but also for teachers of Slovene in primary and secondary schools, their pupils and students, those who learn Slovene as the second or foreign language, and for all web users who try to solve their language problems by searching the web instead of consulting their bookshelves. To satisfy all types of users we designed the new web concordancer to be as user-friendly as possible, including automatic lemmatization of words in the query, and immediate presentation of data in filters on the left side of the interface.
WHAT KIND OF TEXTS ARE IN GIGAFIDA?
Gigafida consists of texts which were published between 1990 and 2011. Text come from printed sources and from the web. Printed part contains fiction, non-fiction and textbooks, and periodicals such as daily newspapers and magazines. Text originating from the web were published on news portals, pages of big Slovene companies and more important governmental, educational, research, cultural and similar institutions. Percentages of text types are shown in the chart below.
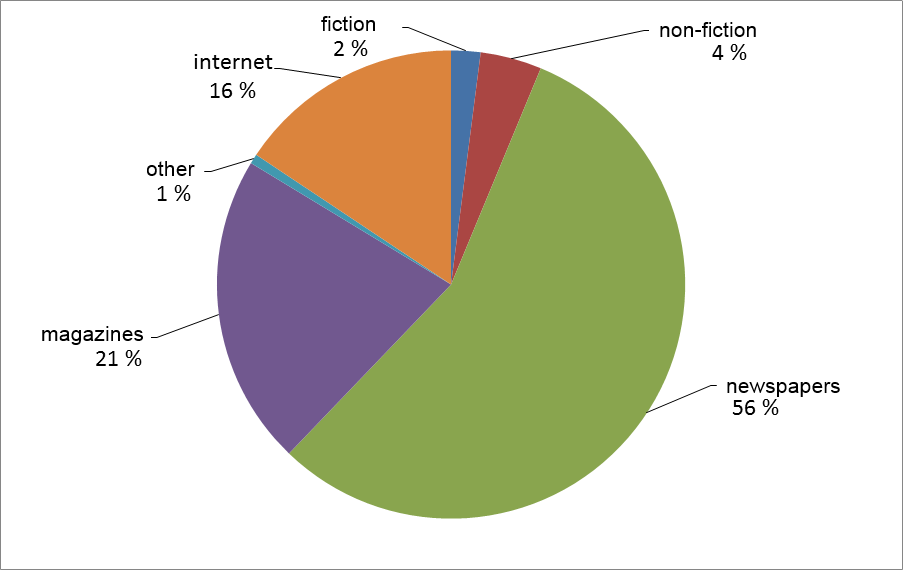
Almost all the FidaPLUS corpus (2006), the previous version of the Slovene reference corpus, was included in Gigafida, as well as all the new material from 2006 onwards. From the first stages of the project, balanceness of text types was included in our plans and realized in the 100-million word corpus KRES.
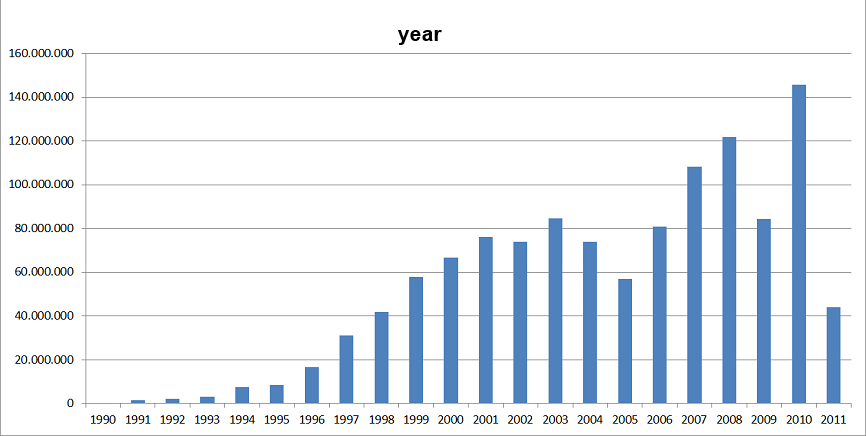
The number of words divided by year in the chart below shows gradual increase of the quantities of the collected material.
DOES GIGAFIDA CONTAIN ONLY RAW TEXTS?
Besides raw text, Gigafida contains other kinds of information. Each of the 39,427 corpus documents includes the information about the source (npr. Mladina magazine, Delo, Dnevnik newspapers), year of publication, text type (fiction, newspaper), the title and autor if they are known. In addition of document meta-data, the corpus is tagged which means that each word is attributed with two additional types of information. The first one is the basic form of the word, also called a lemma (e.g. jagode, jagodi, jagodam -> lemma = jagoda), and the seciond one is a morpho-syntactic tag. This tag describes which part-of-speech the word belongs to (noun, verb, adjective, etc.), and what are its morphological features (e.g. gender, case, number). Since the corpus contains large quantities of texts tagging was automatic, it was done by a tagger called Obeliks, also developed within the “Communication in Slovene” project. You can test it in the web service.
OWNERSHIP AND AVAILABILITY
The owner of the Gigafida corpus is Ministry of Education, Science and Sport. The corpus is freely available online and it can be accessed through various web concordancers. The database of the corpus in textual format (XML) is available only if a special contract is signed between the owner and the user, due to the need to copyright protection of the text providers. If you want to obtain the corpus in XML format or include it in your concordancer, write to the address info@slovenscina.eu. The ccGigafida corpus, a 9-percent part of the Gigafida corpus is avaliable also under Creative Commons licence and can be downloaded from the open corpora page.
COLLABORATORS
Head of text acquisition: Nataša Logar Berginc
Text acquisition: Simon Šuster, Matic Korošec, Teja Roglič, Mateja Grča, Urška Sančanin, Tamara Ambrožič, Mitja Knapič, Nataša Gliha Komac
Text conversion: Simon Šuster
Web crawling and text processing: Miha Grčar
Linguistic annotation: Obeliks tagger (Miha Grčar, Matjaž Juršič, Simon Krek, Kaja Dobrovoljc)
XML scheme, TEI validation: Tomaž Erjavec
Web concordancer concept: Simon Rigač, Špela Arhar Holdt, Iztok Kosem, Simon Krek, Polona Gantar, Nataša Logar Berginc
Web concordancer programming: Rok Rejc, Simon Rigač
BIBLIOGRAPHY
Conference papers, Journal articles, Books
Špela Arhar Holdt, Iztok Kosem in Nataša Logar Berginc (2012): Izdelava korpusa Gigafida in njegovega spletnega vmesnika. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan.
Tomaž Erjavec in Nataša Logar Berginc (2012): Referenčni korpusi slovenskega jezika (cc)Gigafida in (cc)KRES. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan.
Nataša Logar Berginc, Miha Grčar, Marko Brakus, Tomaž Erjavec, Špela Arhar Holdt in Simon Krek (2012): Korpusi slovenskega jezika Gigafida, KRES, ccGigafida in ccKRES: gradnja, vsebina, uporaba. Ljubljana: Trojina, zavod za uporabno slovenistiko; Fakulteta za družbene vede.
Nataša Logar Berginc in Iztok Kosem (2011): Gigafida – the new corpus of modern Slovene: what is really in there? Slavicorp conference. Dubrovnik.
Nataša Logar Berginc in Simon Krek (2010): New Slovene corpora within the “Communication in Slovene” project. Slavicorp conference. Warsaw.
Nataša Logar Berginc in Simon Šuster (2009): Gradnja novega korpusa slovenščine. Jezik in slovstvo 54/3–4. 57–68.
Videolectures
Nataša Logar (2009): Korpus: niso ga samo besede.
