WEB CONCORDANCERS
 |
 |
 |
To play around with concordancers click on the images above.
WHAT IS A WEB CONCORDANCER?
Web concordancers are computer programs which enable searching in large collections of texts – corpora – on the web. The interface developed in the Communication in Slovene project is simple, it was designed to enable user-friendly experience (also in schools). Through the interface, users can analyse and monitor how real modern Slovene is used, primarily in the two written corpora Gigafida and Kres, and the spoken corpus Gos.
HOW DID WE CONCEPTUALIZE THE CORCORDANCER?
The concordancer was designed by following good practice in other web concordancers, findings of corpus linguists and also opinions and comments of users. In our analyses and questionnaires it turned out that many of them do not use available features in the previous version of the concordancer or are not aware of them at all. We were surprised to learn that more than a quarter of users did not know about the possibility to search word lemmas and more than a third did not know anything about morpho-syntactic tagging. Results of the questionnaire showed that a large part of regular users actually do not have the appropriate knowledge to use this language resource properly or effectively. The final conclusion of the analysis was the decision that search routines have to be simplified to the extreme, and browsing and further processing of corpus data have to be intuitive and very easy to understand.
WHAT ARE ITS BASIC CHARACTERISTICS?
The concordancer does not require registration or authentication and it is not necessary to consult manuals, help pages or other information about the corpus before the first search. The first activity expected from the user is entering the query into the query window, and this window is actually the only item on the initial screen of the concordancer. In its intuitivneness, corpus search should resemble the searching the web with popular search engines.
We can search the corpus by entering a search string in the query window. The string could be a word (e.g. medved (bear), a combination of words (e.g. polarni medved (polar bear)) or a string of words containing also punctuation marks (e.g. kljub temu, da (in spite of). Advanced search enables users to employ additional filters, such as morpho-syntactic features of the search word or words appearing in the context. One does not have to study a special query language, filters can activated by selecting the desired features on predefined tables in the interface.
WHICH ARE THE NEW FEATURES?
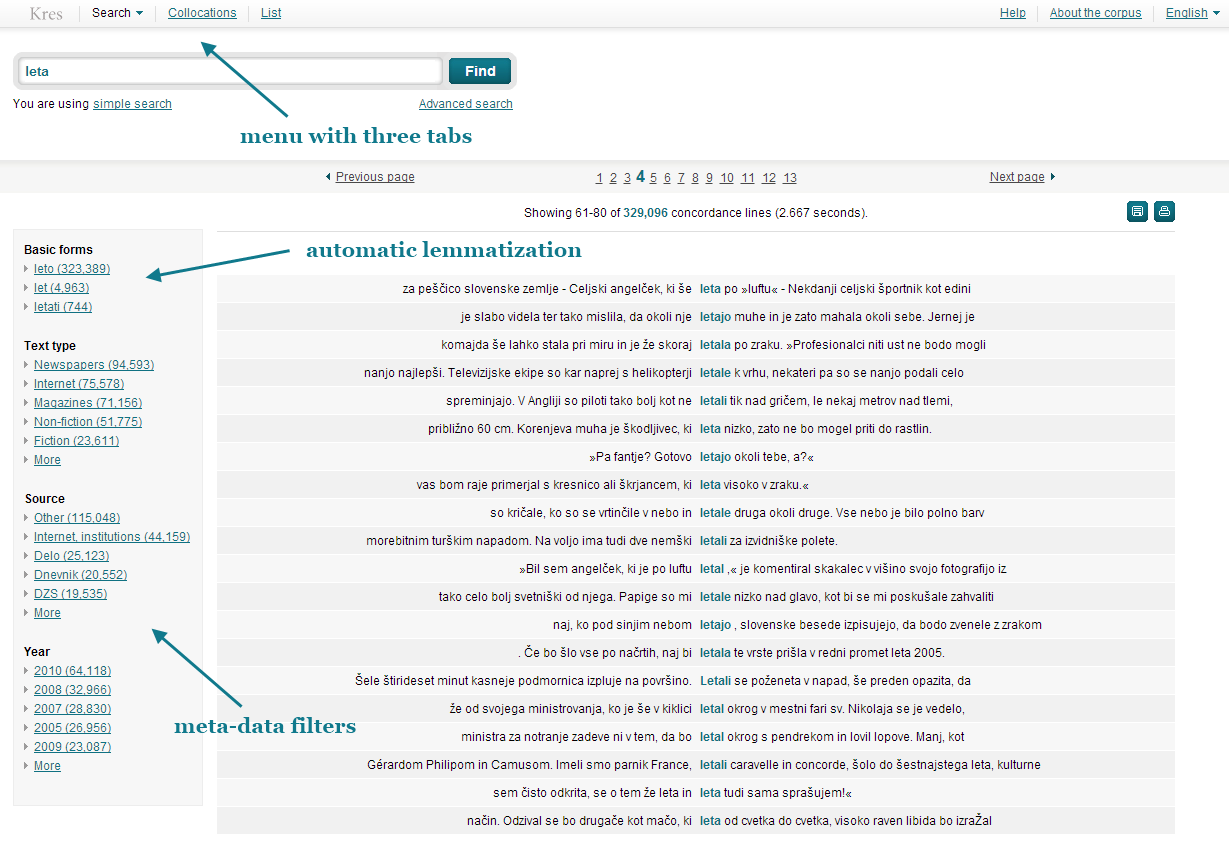
A significant difference in comparison with previous Slovene web concordancers is the introduction of automatic lemmatization in basic search. In the FidaPLUS concordancer the user had to specify that he or she is interested in all forms of the search word, while in the new concordancer one has to specify the converse condition – putting the query into quotes specifies that only the exact search string, and therefore one particular form in the morphological paradigm, should be shown in the result. As Slovene is a highly inflected language this kind of corpus searching is more intuitive.
An important new feature are filters on the left side of the screen. Filters appear automatically in each query and are based on the meta-data contained in each corpus document. In this way users can learn about the frequency of the search string according to different criteria such as the year of publication, text type etc. Filters also enable users to narrow down their result with one click, for example, they can choose only those concordances with text from the web, or only those collocates which are tagged as verbs in the corpus.
Functional clarity of the interface was achieved by offering the user only those functions and links that are really needed in each particular step of the work. Basically, this is reflected in the menu with three tabs, each tab enabling a different kind of corpus search and analysis: concordances, collocations and word lists. All tabs have similar features – the possiblity to export and print data, data filters, query window, search history etc. which can be found in the same part of the interface. At the same time, features which are different follow the most suitable presentation of the specific data they contain (concordances, lists etc.).
OWNERSHIP AND AVAILABILITY
Web concordancers are results of two projects: concordancers for written corpora Gigafida and Kres were made in the “Communication in Slovene” project, and the concordancer for the spoken corpus Gos was made in the “Web concordancer for the national corpus of spoken Slovene” project. The owner of the written corpus concordancer is the Ministry of Education, Science and Sports. For further informaction or if you wish to use the concordancer for your corpus please write to the address info@slovenscina.eu.
AUTHORS AND COLLABORATORS
Gigafida and KresConcept: Simon Rigač, Špela Arhar Holdt, Iztok Kosem, Simon Krek, Polona Gantar, Nataša Logar Berginc
Design and programming: Rok Rejc, Simon Rigač
Project leader (“Web concordancer for the national corpus of spoken Slovene”): Darinka Verdonik
Project partners:
- Faculty of Electrical Engineering and Computer Science, University of Maribor (leader)
- Amebis, d. o. o., Kamnik
- Faculty of Arts, University of Ljubljana
- Trojina, Institute for Applied Slovene Studies
Concept (prototype, coordination): Simon Rigač
Design and programming: Rok Rejc, Simon Rigač
BIBLIOGRAPHY
Iztok Kosem (2010): User-friendly concordancers for corpora of Slovene. Konferenca Slavicorp. Varšava, Poljska.
Iztok Kosem (2010): Something for teachers and something for learners: the design of a user-tailored concordancer for Slovene Corpora. Teaching and Language Corpora (TALC8) conference. Brno, Češka.
Zwitter Vitez, Ana, 2010: Kako in zakaj uporabljati govorni korpus slovenskega jezika. Predstavitev na konferenci Korpusi, več kot le statistika, Ljubljana, FDV.
Verdonik, Darinka, Zwitter Vitez, Ana, Romih, Miro, Krek, Simon, 2010: Konkordančnik za govorni korpus GOS. Erjavec, Tomaž, Žganec Gors, Jerneja (ur.): Zbornik Sedme konference Jezikovne tehnologije – IS 2010. Ljubljana: Institut Jožef Stefan. 12-15.
Verdonik, Darinka, 2011: Govorni korpus kot lektorjev priročnik. Krakar Vogel, Boža (ur.): Slavistika v regijah – Maribor: Zbornik Slavističnega društva Slovenije. Ljubljana: Zveza društev Slavistično društvo Slovenije. 171-173.
Verdonik, Darinka, Zwitter Vitez, Ana, 2011: Slovenski govorni korpus Gos. Ljubljana: Trojina, zavod za uporabno slovenistiko.
Zwitter Vitez, Ana, 2011: Korpus Gos in njegova uporaba v raziskovalne, didaktične in ljubiteljske namene. Kranjc, Simona (ur.): Meddisciplinarnost v slovenistiki – Obdobja 30. Ljubljana: Center za slovenščino kot drugi/tuji jezik. 559-564.
Špela Arhar Holdt, Iztok Kosem in Nataša Logar Berginc (2012): Izdelava korpusa Gigafida in njegovega spletnega vmesnika. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan.
Nataša Logar Berginc, Miha Grčar, Marko Brakus, Tomaž Erjavec, Špela Arhar Holdt in Simon Krek (2012): Korpusi slovenskega jezika Gigafida, KRES, ccGigafida in ccKRES: gradnja, vsebina, uporaba. Ljubljana: Trojina, zavod za uporabno slovenistiko; Fakulteta za družbene vede.
