SLOVENE TAGGER
|
To play around with the tagger click on the image on the left or follow link. You can also download the tagger. |
WHAT IS A TAGGER?
A tagger is a computer program which splits a text into smaller units or words and adds different types of linguistic information to each word, eg. its part of speech, other morphological features (gender, case, etc.), and its lemma if the word has more inflected forms. The Obeliks tagger was developed as part of the Communication in Slovene project and consists of three components: a segmentation and tokenization module which segments the text into sentences and words, the part-of-speech module itself which assigns information about the part-of-speech and its properties to each identified word, and a lemmatization module which assigns lemmas to each word. You can try out how it works by clicking on the image above.
HOW ACCURATE IS THE TAGGER?
Obeliks tagger assigns part-of-speech categories and their properties to words according to the JOS tagset which was defined in the Linguistic annotation of Slovene project. All combinations of categories, attributes and their values in the tagset amount to 1,902 possible tags which represents an enormous challenge for the tagger. Tipical tagsets for English – a morphologically relatively simple language – includes less than 100 tags, the most common ones around sixty. Since the annotation is performed by a machine which relies on statistical probability of selection between several possible tags the tagger cannot attribute all the tags or lemmas accurately. Accuracy of tagging in terms of using the whole tagset with all categories, attributes and values is 91.34%. Top level part-of-speech categories (noun, verb, pronoun etc.) are tagged with 98.30% accuracy. Lemmatization is performed with 97.88% accuracy if capitalization is considered while on the level of the character string (all letters normalized) the percentage rises to 98,55.
HOW CAN I USE THE TAGGER?
The tagger can be tested on the web page označevalnik.slovenščina.eu. Online service is intended for tagging shorter texts and as a demonstration of tagger performance. Tagged texts can be viewed in two formats. The first one is XML TEI (Text Encoding Initiative) which is intended for further processing with computational tools, or import into concordancers. The second one is inteded for viewing on the web and shows three types of data in table format: word form, lemma and morpho-syntactic description or tag. Mouse-over function reveals a detailed explanation of the tag – on the image below the explanation of the tag belonging to the noun “skupščina” in the sentence “Generalna skupščina razglaša to splošno…” can be seen. To tag larger quantities of text you can use the freely-available downloadable application.
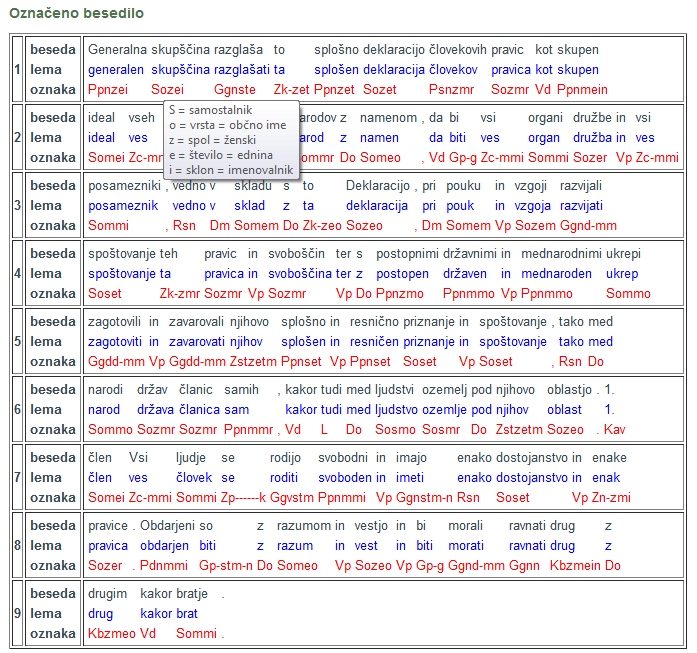
Example of a tagged text in the online format: the beginning of the Universal Declaration of Human Rights (UN).
HOW DOES THE TAGGER ACTUALLY WORK?
The tagger – as one of the functions of Obeliks – is based on the principle of supervised machine learning. This means that it learns to tag texts from manually tagged examples found in the training corpus. In the training phase the tagger builds a knowledge model which enables the tagging of new, unknown words. Basic components of the tagger are: (i) suffix trie, (ii) algorithm for creating feature vectors, (iii) algorithm for tagging. For tagger training we need manually tagged corpus and lexicon which are used to build suffix trie. After that a feature vector is created for each word in the training corpus. These are tagged with morpho-syntactic descriptions of particular words, and therefore the algorithm for supervised learning which creates a knowledge model on the basis of the tagged vectors can be used. The knowledge model incorporates the information about the characteristics of feature-value pairs which group particular morpological categories and which separate them. The algorithm used by Obeliks for training is based on maximum entropy and is frequently used for tagging sequences. A more detailed and technical description of the tagger is available in a journal article and a video lecture.
LICENCE AND DOWNLOAD
Obeliks is freely available as a web service and as a downloadable application which can be used to tag larger quantities of texts. The application is available on two web sites: on the Communication in Slovene project site and on the SourceForge portal. Obeliks is distributed under the Lesser General Public Licence version 3.0 or (LGPLv3).
AUTHORS AND COLLABORATORS
Morhpo-syntactic tagger: Miha Grčar, Matjaž Juršič in Jan Rupnik
Rules for segmentation, tokenization and lemmatization: Simon Krek, Kaja Dobrovoljc in Miha Grčar.
Lemmatizer: Matjaž Juršič (lemmatizer as a stand-alone programme)
BIBLIOGRAPHY
Miha Grčar, Simon Krek, Kaja Dobrovoljc (2012): Obeliks: statistični oblikoskladenjski označevalnik in lematizator za slovenski jezik. V T. Erjavec, J. Žganec Gros (ur.): Zbornik Osme konference Jezikovne tehnologije. Ljubljana: Institut Jožef Stefan.
Videolectures:
Miha Grčar: Oblikoskladenjski označevalnik SSJ, presentation on the “Corpus, more than just statistics” conference (Faculty of Social Sciences, University of Ljubljana, 5th February 2010)
