DESCRIPTION
|
Click on the image on the left to explore Sloleks, Slovene morphological lexicon with 100,000 words. |
WHAT IS SLOLEKS?
WHY DO WE NEED SLOLEKS?
The ISO standard format Lexical Markup Framework was selected for structuring the information in the lexicon. The format is the latest result of a long series of standardization projects for recording European and other language data. The lexicon as part of language technology applications needs to be compatible with two other closely-related parts of the project: a training corpus and a tagger. Word classes (or categories) and their morphosyntactic features for these two resources are based on the JOS project specifications and are found in both the training corpus and the lexicon. Similarly, the same tagset is used by the tagger, making it possible to directly link the tags in the lexicon and the tags in the Gigafida and Kres corpora. Consequently, the information on the frequency of each word form in the corpus could be included in the lexicon database. In an online search engine of Sloleks both databases are connected, so we can see the concordances of any word form by clicking on the link in the “frequency” column.
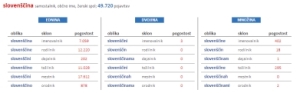
SLOLEKS IN NUMBERS
Sloleks lexicon contains 100,784 entries or lemmas and 2,791,919 word forms with formalized grammatical descriptions.
| Element | Description | Number | Part of speech | Number | |
| <LexicalEntry> | Element containing a lemma and its word forms | 100,784 | Nouns | 54.254 | |
| <Lemma> | Canonical or dictionary word form | 100,784 | Adjectives | 26,597 | |
| <WordForm> | Element with info about a word form | 2.773.511 | Verbs | 10.242 | |
| <FormRepresentation> | Element with info about a word form variant | 2.791.919 | Adverbs | 6.906 | |
| <RelatedForm> | Link to related lexical entries (in terms of word-formation) | 65,951 | Numerals | 2,240 | |
| <Sense> | Element with semantic information | 74 | Prononuns | 169 | |
| <Definition> | Element containing a definition | 74 | Prepositions | 96 | |
| <ListOfComponents> | Element contatining parts of a multi-word expression | 3 | Interjections | 85 | |
| <MWELex> | Element with a multi-word expression | 2 | Abbreviations | 70 | |
| <MWENode> | Part of the lexicon with multi-word expressions | 1 | Particles | 68 | |
| <Lexicon> | Root element | 1 | Conjunctions | 54 | |
| Multi-word expressions | 3 | ||||
| Total | 100,784 |
AUTHORS AND COLLABORATORS
Compilation of the lexicon: Peter Holozan, Simon Krek, Kaja Dobrovoljc, Miro Romih
Computational processing of the lexicon: Peter Holozan, Miha Arčan
Manual processing of the lexicon: Kaja Dobrovoljc
Integration of the lexicon in the Obeliks tagger: Miha Grčar, Matjaž Juršič
BIBLIOGRAPHY
Guidelines
Simon Krek, Tomaž Erjavec, Peter Holozan (2008): Specifikacije za leksikon besednih oblik (kazalnik 3). Projekt Sporazumevanje v slovenskem jeziku.
Articles and books
Špela Arhar, Učni korpus SSJ in leksikon besednih oblik za slovenščino, Jezik in slovstvo 54/3–4, 2009, 43–56.
